講義ノート集
KUT経・マネ/プログラミング系授業
第4回 変数とメモリ
代入(付値)とは何か
本講義の受講者にとって、Rの次のような操作は至極ありふれたものだと思います。
# コード1
x <- c(1,2,3)
y <- x
x[2] <- 5
print(x)
print(y)
上記のコマンドを実行したときに、どのような結果が出力されるかを答えられない人はいないでしょう。実際にRの対話的インタープリタを起動するか、VS Code上で実行してみれば良いでしょう。
> print(x)
[1] 1 5 3
> print(y)
[1] 1 2 3
>
しかし、コード1で実際に何が起きているのかを正しく説明できる人はあまり多くないと思います。多くの人が次のように考えているのではないでしょうか?
- 変数xにベクトル(1,2,3)が代入される
- 変数yに変数xの値、つまり(1,2,3)がコピーされる
- 変数xの第2要素が5に書き換えられる
- 変数xの値が出力される
- 変数yの値が出力される
しかし、実際に起きていることは、上記と少し違います。今回の目標はこれを理解することとします。今回の講義で、変数に値を代入するときRやPythonでは何が起きているのかが、ある程度分かるようになります。第1回で学んだメモリやアドレスの概念が必須になります。
ハコ型代入
上記の説明がどのように間違っているかを説明する前に、初学者向けの書籍に良く見られる「箱の比喩」を用いた代入の説明について解説しておきます。
箱を用いた説明とは、次のようなものです。
下図のように、変数
xに1を代入するということは、xという箱に1という値を入れることであり、yにxを代入するということは、xに入っている値1をコピーしてyという箱に入れることである。
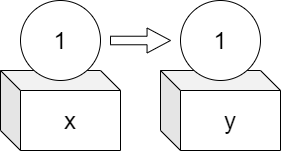
このような説明は、C言語のようなプログラミング言語では正しい比喩ですが、RやPythonでは正しくありません。特にPythonでは正しい理解を妨げる説明です。
C言語では、次のようにして、予めxやyが整数であることを変数の作成時に宣言します
int x,y; // x,yが整数であることを宣言
ソースファイルにこの宣言を見つけたCのコンパイラは、マシン語に変換する際に、xやyといった変数名をメモリのアドレス(実際にはメモリ領域)あるいはレジスタ名といったもので置き換えてしまいます。
したがって、
y = x; // xの値をyに代入
という代入操作は、あるアドレスのメモリ領域に格納されている値を別のメモリ領域にコピーすることを意味します。したがって、メモリ領域を箱と考えれば、箱の比喩は正しく実際に起こっていることを表しています。
ラベル型代入
プログラミングの世界では、124や”c”のような具体的な数値や文字だけではなく、それを操作するための付属的な情報を合わせもつものをオブジェクトと呼びます。
オブジェクトは、表面的には数値や文字ですが、実際には数値や文字を格納する領域以外にもメモリ領域を占有しています。C言語の整数や文字列は、値を格納する分だけのメモリ領域しか占有しないので、オブジェクトではありません。一方、PythonやRの数値や文字列はすべてオブジェクトです。
RやPythonでの代入の説明でより現実に近いのは以下のような比喩です。
下図のように、変数
xに1を代入するということは、1というオブジェクトにxというラベルを貼り付けることであり、変数yにxを代入するという操作は、ラベルxがついているオブジェクトにもう一つyという別のラベルを貼り付けることである。
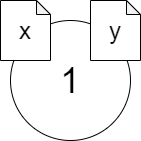
この正しい見方では、1という一つのオブジェクトにx、yという二つのラベルが貼り付けられています。このようなラベルのことを参照(reference)と呼ぶことがあります。また、変数xやyはオブジェクト1を参照しているということもあります。
それでは、Rでの代入操作(y <- x)がこのような「ラベル張り」であるということを確かめてみましょう。そのために、Hadley Wickhamが作ったpryrパッケージをインストールしましょう。
install.packages('pryr')
pryrを読み込むと関数addressを使うことができるようになります。addressは、引数として与えた変数(参照)が指し示しているオブジェクトのアドレスを返す関数です。実際に使ってみましょう。
library(pryr)
x <- c(1,2,3)
address(x)
y <- x
address(y)
上のように対話的インタープリタで入力すると、次のような出力が得られます。
> address(x)
[1] "0x183f3110"
> y <- x
> address(y)
[1] "0x183f3110"
>
出力が二つ得られていますが、一つ目の値0x183f3110は、xというラベルが貼り付けられているベクトル(1,2,3)というオブジェクトが格納されているメモリのアドレスを16進数で表したものです(具体的なアドレスの値は、実行時ごとに異なります)。また、二つ目の出力は、yというラベルが貼り付けられているオブジェクトのメモリ上のアドレスですが、これも0x183f3110となっており、xと同じオブジェクトにyが貼り付けられているということが分かります。
このように、C言語とは違ってx、yという別個のメモリアドレスが存在するわけではないことが分かります。
参照カウンタ
ところが、RはCopy on modifyという機構を備えていて、ラベル張りであることを余り意識させない作りになっています。Copy on modify機構について説明するために、まずは参照カウンタ(リファレンスカウンタ)について説明しましょう。以下、Rのヴァージョン3系列(3.5,3.6等)を仮定して話を進めますが、出力はヴァージョン4でも同じになるはずです。(ヴァージョン3と4の違いは課題で取り扱います。)
ベクトルのようなRのオブジェクトは、自分に何枚のラベルがついているかに関する情報を内部に格納しています。換言すると、Rオブジェクトは、自分がいくつの変数(xやy)に参照されているかを知っています。オブジェクトを参照している変数の数の事を参照カウントと呼びます。Rオブジェクトは、内部に自分自身の参照カウントを記憶する参照カウンタを持っています。
参照カウンタの値は、関数pryr::refsによって調べることができます。
> rm(list=ls()) #一応全変数を削除
> x <- c(1,2,3)
> refs(x)
[1] 1
> y <- x
> refs(x)
[1] 2
> refs(y)
[1] 2
>
Copy on modifyメカニズム
さて、次のようにxに代入したベクトル(1,2,3)の内容を書き換えようとするとき、参照カウントが1の場合と2以上の場合では、Rは異なる挙動を示します。
まずxの参照カウントが1の場合です。
rm(list=ls()) #全変数を削除
x <- c(1,2,3)
address(x)
x[2] <- 5
address(x)
上記を実行すると、次のような出力が得られます。
> x <- c(1,2,3)
> address(x)
[1] "0x17f14dd8"
> x[2] <- 5
> address(x)
[1] "0x17f14dd8" #xのアドレスは変わらない
>
上記のように、xの内容を書き換える前後で、xは同じオブジェクトを参照しています。
ところが、xの参照カウントが2以上のとき、つまりxと同じオブジェクトを参照する変数yが存在するとき、異なる挙動が起きます。次を実行してみましょう。
rm(list=ls()) #全変数を削除
x <- c(1,2,3)
y <- x
address(x)
address(y)
x[2] <- 5
address(x)
address(y)
上記を実行すると、次のような出力が得られます。
> rm(list=ls()) #全変数を削除
> x <- c(1,2,3)
> y <- x
> address(x)
[1] "0x17ecbc78"
> address(y)
[1] "0x17ecbc78"
> x[2] <- 5
> address(x)
[1] "0x17ecb598" #xのアドレスが変わった
> address(y)
[1] "0x17ecbc78"
>
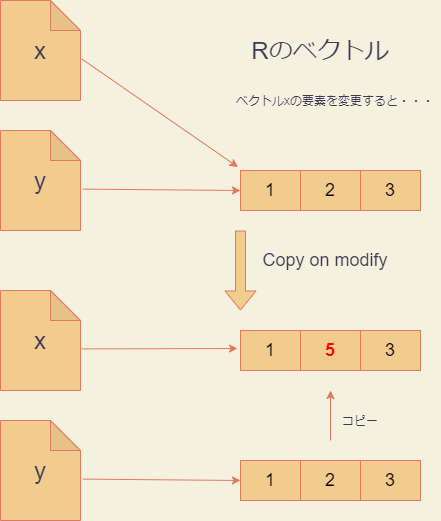
上記のように、参照カウントが2以上になると、オブジェクトの内容を変更する際に、あらたなメモリ領域が確保され、オブジェクトがコピーされてから変更が行われることが分かります。このメカニズムをCopy on modifyと呼びます。
Copy on modify機構のおかげで、Rのプログラマは、オブジェクトがいくつの変数に参照されているかをあまり意識する必要がありません。xの内容を修正したときに、うっかりyの内容まで修正してしまう危険がないわけです。
練習1
-
次のRコードは、二つの参照を持つリストオブジェクトの内容を変更するものである。
pryr::address関数を用いて、上記のコードでCopy on modify機構が働いているかどうか確かめなさい。rm(list=ls()) # 全変数を削除 x <- list(a='A',b='B') y <- x x[['a']] <- 'AA' -
次はさらに複雑な例である。
xはリストを要素にもつリストである。この入れ子になった内側のリストに変更を加えたとき、Copy on modifyは働くか?確かめなさい。rm(list=ls()) x <- list(a=list(b='B',d='D')) y <- x x[['a']][['b']] <- 'BB'
Pythonの挙動
ところが、PythonにはCopy on modify機構がありません。どういうことかというと、オブジェクトがいくつの変数に参照されているかにかからわず、オブジェクトの内容変更に伴うコピーは自動的には起きません。
これを実際に確かめてみましょう。 Pythonにはベクトル型は存在しないので、代わりにリストを使いましょう。たとえば1,2,3という三つの整数を要素にもつリストは次のように作成します。(リストについては、次回詳しく取り上げます。)
>>> x = [1,2,3]
>>> x
[1, 2, 3]
Rのベクトルでは最初の要素にアクセスするにはx[1]と書きますが、pythonのリストではx[0]と書きます。つまり、インデックスは0からはじまります。それを除けばインデクシングのルールはRのベクトルと非常によく似ています。
>>> x
[1, 2, 3]
>>> x[0]
1
>>> x[1]
2
>>> x[2]
3
さてそれでは準備が出来たので実験を開始しましょう。
PythonにおけるRのpryr::addressに対応する関数はビルトイン関数のidです。idは、変数が参照するオブジェクトのアドレスを10進数で返します。まずはpythonの変数が参照であることを確認しましょう。
>>> x = [1,2,3]
>>> y = x
>>> id(x)
2080340453760
>>> id(y)
2080340453760
>>> id(x) == id(y)
True
最後のid(x) == id(y)という式は、Rと同じで、左辺と右辺が正しければTrue、違っていればFalseを返す二項演算です。上記より、確かにpythonの代入がラベル型であることが分かります。なお、id(x) == id(y)は、次のように書くこともできます。
>>> x = [1,2,3]
>>> y = x
>>> x is y
True
“x is y“は、xとyが同じオブジェクトを指しているときにTrue、そうでないときにFalseとなります。
それでは次に、Copy on modifyが働かないことを確かめましょう。
>>> x = [1,2,3]
>>> y = x
>>> x is y
True
>>> x[1] = 5
>>> x
[1, 5, 3]
>>> y # yまで変化した
[1, 5, 3]
>>> x is y # Copy on modifyは起きていない
True
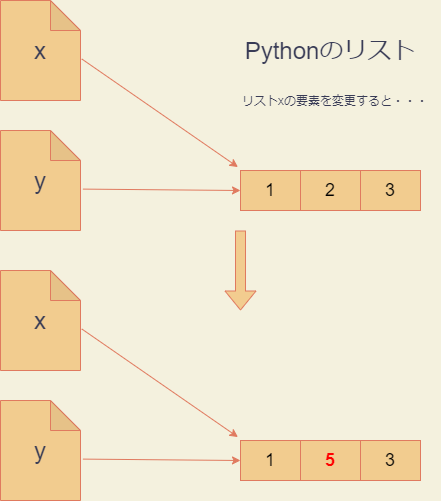
上記のように、複数の参照をもつオブジェクトの内容を変更すると、それを参照する全ての変数の内容が変わってしまいます。下図のように、Rとは違ってPythonはCopy on modifyを行わないからです。
デバッグモードの活用
オブジェクトのメモリアドレスやオブジェクトの同一性がプログラムの中でどのように変化していくかを観察するには、VS Codeのデバッグモードを用いると分かりやすいです(condaコマンドのパスを通している必要があります)。
GitHubディレクトリの下に、varsというディレクトリを作成し、VS Codeで開きましょう。debug.pyというファイルを作成し、次のように記述してください。
x = [1,2,3]
y = x
x[1] = 5
pass
passは、『何もしない』を意味します。
次に、VS Codeの画面左側の虫のマークをクリックしてください。
『実行とデバッグ』というボタンが現れますが、そのすぐ下の、『launch.jsonファイルを作成します』をクリックしてください。
Debug Configurationというパレットが立ち上がりますので、一番上の、Python File Debug the currently active Python fileを選択してください。これで、今選択しているPythonコードをデバッグすることができるようになります。launch.jsonという設定ファイルが作成されますが、閉じてください。
開いているdebug.pyファイルの1行目の左がわをクリックして、赤い印をつけましょう。これをブレークポイントと呼びます。デバッグをするときは、このブレークポイントを一つ以上設定します。
次に、『ウォッチ式』を定義します。画面左側中程にある『ウォッチ式』ペインの『+』マークをクリックして、ウォッチ式を入力しましょう。ここでは次の3つのウォッチ式を入力してください。
- id(x)
- id(y)
- x is y
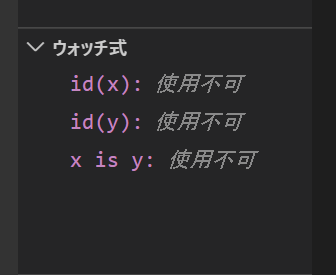
ウォッチ式とは、デバッグ中にリアルタイムで『ウォッチ』したい式のことです。
以上でデバッグの準備が整いました。
ステップイン
デバッグを起動するには、左上の緑色の三角マークをクリックします。
デバッグが起動すると、プログラムが実行され、ブレークポイントの行を実行する直前でストップします。また、画面上に6個のボタンが現れることに注意してください。
これらのボタンは、左から順番に
- 次のブレークポイントまで実行
- ステップオーバー
- ステップイン
- ステップアウト
- 再起動
- 停止
を表します。ステップオーバーとステップアウトは関数に関係があるので、今は説明を保留します。
ここから、ステップインという操作によって、1行ずつコードを評価しながら、ウォッチ式の値がどのように変化していくか観察していきます。
ステップインを表す下向きのやじるしをクリックしてください。すると、ブレークポイントの行が実行され、次の行へとフォーカスが移ります。
左上の『変数』ペインのLocals欄とGlobals欄の両方にx: [1,2,3]というのが現れるはずです。
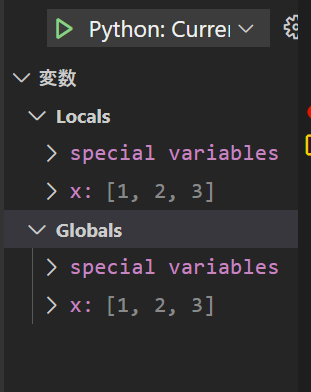
これは、変数xに[1,2,3]という値(オブジェクト)が付値されたということを表します。
同時に、ウォッチ式のペインでは、id(x)の値に数字が現れるはずです。この値は、id(x)の値、すなわちオブジェクト[1,2,3]が位置するメモリのアドレスを表しています。
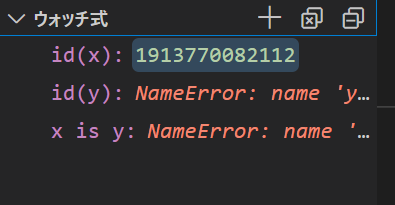
yのほうはまだ代入が起きていないため、ウォッチ式id(y)の値はNameErrorとなっています。
次に、もう一度ステップインしてください。次は、ウォッチ式id(y)の値が表示され、ウォッチ式x is yがTrueになるはずです。id(x)とid(y)の値が同じであることに注意してください。これは、xとyが同じオブジェクトを参照していることを表します。このことは、x is yがTrueになっていることからも分かります。
もう一度ステップインすると、変数ペインのxとyの第2要素が同時に変化することに注意してください。これは、x is yがTrueだったので、予測できたことですね。
最後にもう一度ステップインしてpassの行を実行し、デバッグを終了しておきましょう。
変更と代入の違い
Pythonの初学者にとってちょっと分かりにくいのが、変数xが参照するオブジェクト自体の内容を修正するということと、変数xに別のオブジェクトを代入する・参照させる(参照を付け直す)という二つの操作の違いです。変更では、変数が参照するオブジェクトのアドレスは変化しませんが、代入では変化します。
| 操作 | 参照先のアドレス |
|---|---|
| xが参照するオブジェクト自体の内容を変更 | 変化しない |
| xに別のオブジェクトを代入 | 変化する |
たとえば、次の例では、xとyが同じオブジェクトを参照している状態でxに別のオブジェクトを代入しましたが、yは変化していません。代入操作では、単にxが別のオブジェクトを参照するようになるだけで、もとのオブジェクトには何の影響も与えないからです。
>>> x = [1,2,3]
>>> y = x # xとyは同じオブジェクトを参照
>>> x = [4,5,6] # xに異なるオブジェクトを代入
>>> x
[4, 5, 6]
>>> y # yは変化していない
[1, 2, 3]
>>> x is y # xとyは違うオブジェクトを指している
False
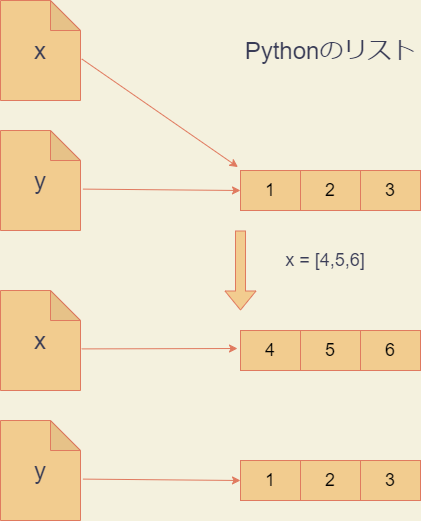
しかしながら、ほんの少しだけコードを変えて次のようにすると、xへの操作は代入ではなく変更になります。yの内容まで変わってしまいますので注意してください。
>>> x = [1,2,3]
>>> y = x
>>> x[:] = [4,5,6] # スライス記法でxの内容を変更
>>> x
[4, 5, 6]
>>> y # yも変わってしまった
[4, 5, 6]
>>> x is y # xとyは同じオブジェクトを参照
True
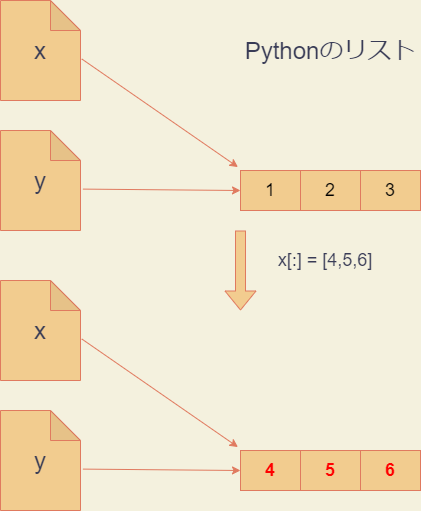
変更したのは1行だけです。ここで用いたx[:]はスライス記法というもので、コロン:は「最初から最後まで、リストの全ての要素」を意味します。スライス記法については、教科書のセクション6.1.2に詳しく説明されているので読んでおきましょう。
スライス記法がどのように機能しているのかを解説するついでに、Pythonに特有のアンパック代入も導入しておきましょう。Pythonでは、次のようにして、複数の変数に一挙に値を代入できます。
>>> x,y,z = [1,2,3]
>>> x
1
>>> y
2
>>> z
3
これをアンパック代入と呼びます。アンパック代入については、教科書のセクション3.2.4に詳しいので読んでおいてください。
上述のスライス記法の構文は、次のようにアンパック代入するのと実質的に同じことをやっていることになります。(実際には少し違います。)
>>> x = [1,2,3]
>>> y = x
>>> x[0],x[1],x[2] = [4,5,6]
>>> x
[4, 5, 6]
>>> y
[4, 5, 6]
>>> x is y
True
これを見れば、スライス記法による代入が、実際にはxが指すリストオブジェクトの内容を変更してしまっているのが分かるでしょう。
実際にはスライス記法による代入は、アンパック代入とは少し違って、左辺の要素数と右辺の要素数が違っても構いません。従って、いままで[1,2,3]があったところに[1,2,3,4]を代入することができます。
>>> x = [1,2,3]
>>> y = x
>>> x[:] = [4,5,6,7]
>>> x
[4, 5, 6, 7]
>>> y
[4, 5, 6, 7]
>>> x is y
True
この操作では、一見、数字3個分のメモリ領域に4個めの数字を詰め込んでいるように見えます。ここでは種明かししませんが、このような一見無理のある代入をしたときにメモリ上で何が起きているのか、想像してみてください。そのような想像が、プログラミングのための思考能力を鍛えることになります。
練習2
ここでは、スライス記法の働きを、VS Codeのデバッグモードで確かめてみましょう。ウォッチ式をid(x)、id(y)、x is yの3つに設定し、次の2つのコードをステップイン実行し、ウォッチ式の変化がどのように異なるか観察してください。
x = [1,2,3]
y = x
x[:] = [4,5,6] # スライス記法でxの内容を変更
pass
x = [1,2,3]
y = x
x = [4,5,6] # スライス記法でxの内容を変更
pass
練習3
次のコードにおいて、x[1]の変更がyの値に影響を与えるかどうか予想してから、実行して確かめてください。
>>> x = [0,1,2]
>>> y = x[1]
>>> x[1] = 5
>>> print(y) # いくつになるか?
>>> x = [0,1,2]
>>> y = x[:]
>>> x[1] = 5
>>> print(y) # 変わっているか?
ミュータブルとイミュータブル
Pythonでは、代入と変更の違いに関連して、初学者を混乱させるミュータブルなオブジェクトとイミュータブルなオブジェクトという概念があります。ミュータブルなオブジェクトは内容の書き換えが可能なオブジェクトであり、イミュータブルなオブジェクトとは、書き換え不可能なオブジェクトです。
| 分類 | データ型 |
|---|---|
| ミュータブル | リスト(list)、辞書(dict)、集合(set) |
| イミュータブル | 整数(int)、浮動小数点数(float)、文字列(str)、ブール値(bool)、タプル(tuple) |
ミュータブルとイミュータブルが紛らわしい概念であるのは、それが変数と定数の概念に、一見似ているからです。
定数という概念はC言語などに現れる概念で、値の変更を禁止された変数のことです。しかしながら、PythonにはC言語のような定数は存在しません(TrueやFalse、Noneといった特殊なビルトイン(組込み)定数が存在するのみです)。
Pythonの変数は、いつでも好きなオブジェクトに貼り付けられるラベルです(箱ではありません)。箱ではなくラベルですから、イミュータブルなオブジェクトからイミュータブルなオブジェクトに付け替えられますし、イミュータブルなオブジェクトからミュータブルなオブジェクトに付け替えることも可能です。
実際、文字列はイミュータブルですが、次のコードは全く正常であり、何のエラーも起きません。
# %%
x = "First"
x = "Second"
x = "Third"
一方、イミュータブルやミュータブルは、ラベルが参照しているオブジェクトの性質であり、定数や変数とは異なる概念です。文字列はイミュータブルなので、その内容を変更することはできません。
# %%
x = "Immutable"
x[0] = "i" #エラーが起きる
上記2行目は、”Immutable”という文字列オブジェクトの最初の要素”I”を”i”に入れ替えよ、という許されない命令です。したがってエラーが出ます。
Traceback (most recent call last):
File "test.py", line 2, in <module>
x[0] = "i"
TypeError: 'str' object does not support item assignment
よくある初学者のミスは、次のように、文字列の一部をスライスで変更しようというものです。
>>> x = "This is Python."
>>> x[0:4] = "It"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
しかし同じことをリストで行うのは、全く正しい操作です。
>>> x = [1,2,3,4,5,6]
>>> x[0:4] = [1,2]
>>> x
[1, 2, 5, 6]
>>>
このように、イミュータブルやミュータブルは、オブジェクトの性質であって、変数そのものの性質ではないことに注意しておきましょう。
イミュータブルオブジェクトの再利用
最後に、イミュータブルオブジェクトとメモリ利用に関連して、一つ注意事項を述べます。これは、Pythonプログラミング上はほとんど問題になりませんが、Pythonのメモリ利用を研究をする上で留意しておくべきことです。
同じオブジェクトを二つ以上の変数が参照しているときに問題が生じるのは、オブジェクトに変更が加えられたときだけであることに注意してください。従って、オブジェクトがイミュータブルである場合は、いくつの変数がそのオブジェクトを参照しているかということは、Pythonのプログラマにとって全く問題になりません。
この事実を利用して、Pythonは、シンプルなイミュータブルオブジェクトに関しては、自動的に再利用するようになっています。
>>> x = 1
>>> y = 1
>>> x is y
True
>>> x = 'a'
>>> y = 'a'
>>> x is y
True
上記では、xとyに独立に1を代入したはずが、xとyは同じオブジェクトを参照していることが分かります。整数オブジェクトはイミュータブルなので、これは全く問題になりません。xが指し示す整数オブジェクト1の内容をうっかり変更してしまって、予期せずyの変更を招く危険がないからです。文字列オブジェクト'a'についても同様です。また、TrueやFalseのブール型オブジェクト、「からっぽ」を意味するNoneオブジェクト等も必ず再利用されます。
一方で、どれだけシンプルであろうとも、ミュータブルなオブジェクトは再利用されず、代入のたびに新たなメモリ領域が確保されます。
>>> x = [0]
>>> y = [0]
>>> x is y
False
また、イミュータブルであっても、そもそも利用される確率の小さいオブジェクトは、再利用されません。
>>> x = 100000
>>> y = 100000
>>> x is y
False
これは、利用頻度の小さいオブジェクトをメモリ上に確保したままにすると、メモリの利用効率が悪くなるからです。
こういった事柄は一見些細な事柄ですが、Pythonのメモリ利用を研究する上でつまづくポイントになるので、知っておいて損はないでしょう。
動的型付け
今回の講義を通して、『変数』という言葉を特に断りもなく使って来ました。そして、変数へ何らかの値を代入するということは、ラベルをオブジェクトに貼り付けることなのだと説明しました。ラベルが変数名であり、オブジェクトが値です。
Pythonのような言語では、変数名はラベルでしかなく、一つの変数名を、基本的にいつでもどのようなオブジェクトにでもラベルとして貼り付け、貼り付けかえることが可能です。xは整数にしか貼り付けてはいけないとか、yは関数にしか貼り付けてはいけないとか、そういう制約はありません。
したがって、次のようなコードが完全に機能します。
# %%
import sys as x # xはモジュール
print(x)
x = 1 # xは整数
print(x)
x = "string" # xは文字列
print(x)
x = [1,2,3] # xはリスト
print(x)
def x(): # xは関数
print('I am x.')
print(x)
x() # xを関数として呼び出した
コードの詳細はまだわからないと思いますが、重要なのは、同じ”x”という変数に、「モジュール」が代入され、整数が代入され、文字列が代入され、リストが代入され、関数が代入されていることです。このコードの出力は、次のようになります。
# 出力
<module 'sys' (built-in)>
1
string
[1, 2, 3]
<function x at 0x7fb1ac7938b0>
I am x.
上記の出力は、最後の行を除きすべてprint(x)の出力です。これを見ると分かるように、xは、モジュール、整数、文字列、リスト、そして関数へと変化しています。
このようにPythonでは、最初に『xは整数だよ』とか、『xはモジュールだよ』と言った宣言をしません。x(が指すオブジェクト)のデータ型は、動的に変化し得るのです。このような言語の性質を動的型付けと呼びます。それに対して、C言語やJavaがそうであるように、『xは整数だよ』『xは配列だよ』といった宣言をし、そのあとはずっと同じ型のデータしか格納できない、といった性質を静的型付けと言います。
動的型付けの利点は非常に柔軟なプログラミングができるということです。なぜならば、プログラムにおいて、xのデータ型に依存した処理を、ギリギリまで遅らせることができるからです。それどころか、場合によっては、最後まで型を気にする必要すらないからです。たとえば、print(x)と書くとき、xがどんな型をもっているのかなど、(ほとんど)気にする必要はありません。
一方、静的型付け言語だと、xが整数なのか、文字列なのか、最初に決めてしまわならないし、最後まで気にしなくてなりません。従って、往々にして、型ごとに別々のコードを書かなくてはならないことになります。
一方、動的型付け言語の欠点は、コードが実行されるまでxのデータ型がわからないため、xが現れるたびにインタープリタが逐一xの型を判断して、型に応じた適切な処理を実行しなくてはならないことです。そのコストは、実行速度の低下となって現れます。それに対して静的型付け言語は、最初から最後までxのデータ型が固定されているので、逐一データ型をチェックする必要はありません。静的型付け言語では、x+yという表現が出たとき、xは整数か、浮動小数点数か、文字列か、と問う必要はないのです。
変数にまつわる用語
すでにお気づきのように、Pythonのような動的型付け言語においては、変数という言葉を関数やモジュールと言った言葉からわざわざ切り離して定義する意味はほとんどありません。そこで、本講義では、変数という言葉は、ラベルを意味するにすぎず、ときには数値であったり、関数であったり、モジュールであったりしても良いとします。要するに何らかのオブジェクトを参照している記号であれば、それは変数です。
また、名前、識別子、記号と言った言葉も入り乱れて出てきますが、これらは大枠において変数と同じ意味であり、何にでも貼り付けられるラベルを意味します。それではなぜ色々な呼び名が出てくるのかと言うと、読み手にとっては余り重大な意味はありません。往々にして書き手の気分の問題ですが、強いて言えば、以下のような理由を挙げられます。
- 呼び名によって強調したいポイントが違う
- 確かに僅かな意味の違いはある
- できるだけその場その場で、慣習と直観に従った
例えば名前空間の話をするときは、『名前』が適切ですし、記号表の話をするときは、『記号』が適切であるような気がします。後で出てくるように、ある変数xが『記号表』にはエントリーしているが『名前空間』にはエントリーしていない、という状況があります。そういう状況では、記号xは存在するが、名前xは存在しない、とも形容できるかもしれません。
また、数値や文字列だけでなく関数やモジュールまで含めていることを明確にしたいときは、『変数』よりも『識別子』のほうが良いのではないかと思われます。これはニュアンスの問題でしょう。
しかし、細かな話をさておけば、これらの用語は、少なくとも本講義の用法においては、概ね相互に言い換え可能です。
むしろ、名前とは何か、記号とは何か、という得てして不毛な議論を延々と展開することによって読者を混乱させるよりは、用語に関してある程度フレキシブルであったほうが良いというのが筆者の考えです。こと変数に関しては、少なくとも筆者自身の混乱が完全になくなるまでは、言葉の意味を定めるのはその使用であり、言葉の意味がその用法を定めるのではないという言語ゲーム的なスタンスにかまけておきたいと思います。もしこのような曖昧な姿勢により有識者の怒りを買ったとすれば、悪いのは100パーセント筆者の方であることを予め認めておくことにします。
まとめ
今回の授業では、以下の点について学びました。
- ハコ型の代入とラベル型の代入の違い
- Copy on modifyにまつわるRとPythonの違い
- スライス記法の挙動
- イミュータブル・ミュータブルの意味
次回はリストについてさらに掘り下げて学んで行きます。リストについて掘り下げて学ぶことで、メモリやアドレスという概念がPythonの理解において重要であることが分かるでしょう。
参考書
- 『R言語徹底解説』(Hadley Wickham著、石田基広、市川太祐、高柳慎一その他訳)(2016) 共立出版. ISBN-13 : 978-4320123939.
宿題(ホームワーク)
- 教科書のセクション2、3を良く読み、今回の講義では説明されなかった細かい文法的事項を確認してください。
- Pythonでは、ある特定の範囲に含まれる絶対値の小さな整数については、プログラムの実行中ずっとメモリの中に保持され、何回でも再利用されるようになっています。そのような「再利用される」整数のうち、最も値の小さな整数(これは負の整数)と最も値の大きな整数を特定してください。自分で調べても構わないし、インターネットで検索しても構いません。
- Copy on modifyメカニズムの挙動に関して、Rのヴァージョン3系統(ヴァージョン3.5,3.6など)と、ヴァージョン4.0の違いは何でしょうか。説明を試みてください。
課題(アサインメント)
課題2の招待リンクと詳細をMoodleに掲載します。